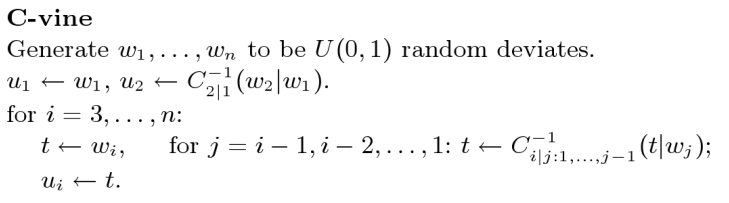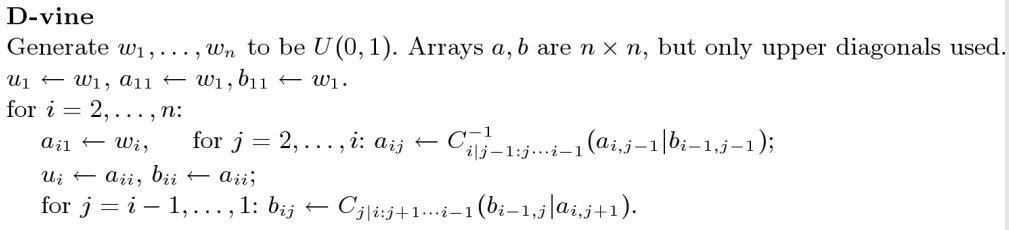So far we have defined a vine as an abstract mathematical object:
a sequence of nested trees. There is no concept of probability in
it. Now we shall bring that in.
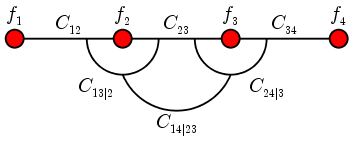
Let V be a regular vine. We associate a univariate density
with each of the variables. These densities may be chosen completely
arbitrarily. Also with each edge we associate a bivariate copula with
density. Thus for the following vine we have specified 4
univariate densities and 6 bivariate copulas:
Notice how we have labelled the copulas using conditioned and
conditioning sets.
A theorem by Bedford and Cooke (2001), which deserves to be
called the fundamental theorem of vines, basically states that for any such
choice there is a unique joint distribution of the variables such
that the univariate desntities are the marginals and for each
edge ij | D the copula of the conditional distribution of
Xi, Xj given XD is Cij|D.
Two points are to be noted about this theorem, one positive and
one negative.
The positive point
How may bivariate copulas do you need to specifiy the dependence
structure completely for n variables? As many as there are
edges in the vine. The lowest level tree has n-1 edges,
the next higher level tree has n-2 edges, and so on, up to
the highest level tree, which has just 1 edge. So the
total number of edges is
(n-1)+(n-2)+...+1 = n(n-1)/2,
which is n choose 2. There is one simple (but wrong) way
of interpreting this: for n variables we are specifiying
the bivariate copulas of all n choose 2 pairs of
variables. While this would also require specification of the
same number of bivariate copulas, but then the choices of tje copulas will not
remain arbitrary. For example suppose that we specify a copula
for ( X1 , X2 ) that forces X1 < X2 with
probability 1. Similarly we can specify a copula for (
X2 , X3 ) which forces X2 < X3 with probability
1. Obviously, we cannot specify a copula for ( X1 ,
X3 ) that forces X3 < X1 with probability
1.
Thus a vine may be considered as a clever way of arranging the
dependence that allows each copula to deal with a separate part of the
dependence. This may be compared to the way a basis generates a
vector space, the span of each vector remaining separate.
The negative point
The theorem above has a somewhat technical condition whose need
may not be readily apparent: we require all the copulas to have
densities. Otherwise the theorem may fail as seen in the
following counterexample:
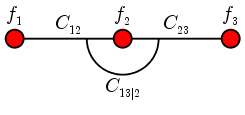
Suppose that we have th following vine:
Let us take each fi to be Unif(0,1) and
C12 and C23 to be the minimum copula, ie,
C12 (x,y) = C23 (x,y) = min { x,y } for x,y∈[0,1].
Also we take C13|2 to be the indepdendence copula
C13|2 (x,y) = xy for x,y∈[0,1].
The minimum copulas force X1 = X2 = X3. Yet the
indepdendence copula wants X1 and X3 to the
indepdendent, which is impossible as X1 and X3
have nondegenerate distirbutions.
However, this does not violate the fundamental theorem, because
the minimum copula does not have a density (wrt bivariate Lebesgue
measure).
Vine copula density
The fundamental theorem guarantees the unique existence of a
joint distribution. In fact, this joint distribution also has a
density (wrt n-dimensional Lebesgue measure). It is
possible to write down the density in a neat way:
f1 × ··· × fn ∏ cij|D ( Fi|D , Fj|D ),
where the product is taken over all edges of the regular
vine. The typical edge is denoted by ij|D. Here
cij|D is the copula density for this edge. Also
Fi|D is the conditional cdf of Xi given
XD.
Why is the funadamental theorem true?
The proof of the fundamental theorem is notationally
cumbersome. However one can see why it should be
true using the following vine.
Here we have 4 variables. Let the joint density be
g1234. Then we know that
g1234 = g1 × g2|1 × g3|12 × g4|123 .
We shall show that the vine (together with the marginals and
copulas) unqiely determine all the densities in the rhs:
g1 is nothing but f1.
Sklar's theorem tells us that a joint distribution is
uniquely determined by the marginals and the copula. We are given
f1, f2 and C12. So we get the joint
distribution of X1 and X2. From this we can
compute the conditional density of X2 given
X1. So we have g2|1.
Proceeding as above we can also obtain
g1|2. Similarly we can get g3|2. Now consider the
joint distribution of X1 , X2 given X3. This is
a bivariate distribution, and so is uniquely specified by the
marginals: g1|2 and g2|3 and the copula
C13|2. Thus we get g13|2, and from this we get
g3|12.
Similarly, we can find g4|123. Make sure you see how!
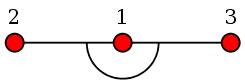
Two special regular vines
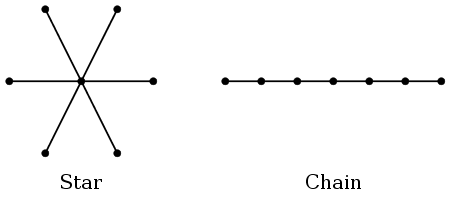
A vine is a nested sequence of trees. Each tree can be of a
different sturctures leding to a complicated vine. There are two
special extreme cases that usually easier to handle. These are
called C-vine and D-vine.
To learn about these we have to recall that a tree means a
connected acyclic graph. Two extreme types of trees are the
following:
You may think of the star configuration as the maximum connectivity
case, and the chain configuration as the minimum connectivity
case.
If all the trees in a vine are of the star type, then the vine is
called a C-vine. If all the trees are of the chain type, then it
is a D-vine.
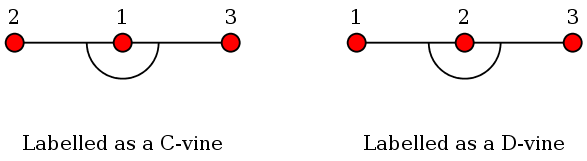
There are standard ways to labelling the variables in a C-vine
and a D-vine. We shall learn about these now.
Notice that a tree of the star type has a centre. For a C-vine we
label the variables in a way such that the lowest level tree has
centre 1, the next tree has centre {1,2}, the next
higher has { {1,2} , {1,3} }, etc.
For a D-vine the labelling is simpler. Just label the variables
in the order of the lowest level tree.
Here is are two examples. Both examples show the same vine, which
happens to be both a C-vine as well as a D-vine. But the
labellings are different:
Simulation from a vine
One way to utilise a model is to simulate data from
it. Simulating rom a vine is a tricky job. It is easiest for a
C-vine, less easy for a D-vine, and quite complicated for a
general regular vine.
Let us understand the basic idea first. If we are given a
bivariate distribution of (X,Y), then one way to simulate from it is to
generate from a marginal of X, and then generate from the conditional
distribution of Y given X. Each random number
generation starts with a Unif(0,1) random variable. So the
bivariate generation requires two Unif(0,1) random
numbers? A moment's thought should convince you that these must
be indepdendent for (X,Y) to have the required bivariate distribution.
Now consider three random variables X,Y,Z. We shall first
generate X, then Y given X. But finally we
shall generate Z given X. So we shall need three
Unif(0,1) random numbers, U,V,W, say. By the
bivariate discussion we know that U,V must be
indepdendent, and so must be U,W. But what about V
and W? They do not need to be indepdendent. In fact, by
allowing them to depend on each other we can introduce
conditional dependence between Y and Z given
X.
This is precisely the idea behind simulation from a C-vine. Let's
take this C-vine:
To
simplify the notation we shall assume that the marginals are all
Unif(0,1). Then we proceed as follows.
First generate U1 from Unif(0,1). Take X1
= U1.
Then generate U12 from Unif(0,1) and use it to
generate U2 from U1. Take X2 = U2.
Then generate U23|1 from Unif(0,1), and use it
to generate U13 from U12.
Use this U13 to generate U3 from
U1. Let X3 = U3.
It is a good exercise to write down the proof that this procedure
indeed produces the correct joint distribution.
Another good exercise is to convince yourself that the same
procedure fails if you label the same vine as a D-vine. This
illustrates the additional difficulty involved in simulating from
a D-vine.
Here is the general algorithm for simulating from a C-vine. It is
taken from chapter 7 of the book Dependence Modelling: Vine
Copula Handbook:
The general algorithm for simulating from a D-vine is more complex:
Fitting a vine to real data
A statistical model is a family of distributions, and is useless
unless there is some way to
select a member of the family that fits a given data
set. Unfortunatley, fitting a vine is not a trivial task. This
involves two things:
Choosing a vine structure
Estimating parameters to the associated copulas.
No best approach is yet known for choosing a vine structure. Here
is a method by Kurowicka that uses a top-down approach. Thhe
basic idea is to account for the strong dependences in the lower
level trees, leaving only the weak one for the upper level
trees. Kurowicka's approach seeks to measure the dependence
strength using partial correlation. Let's explain using an
example. Consider a data set with 5 variables. The first
step is to compute the correlation matrix. Suppose it turns out
to be the following.
We have to convert it to the partial correlation matrix. This is
basically just inverting the matrix and then "normalising" the
inverse. Here normalising means: Treat the inverse as a
convariance matrix, and compute the corresponding correlation
matrix. The following R function will do the normalisation.
normalise = function(mat) {
inv=solve(mat)
D=diag(inv)
M=diag(sqrt(1/D))
ans=M %*% inv %*% M
dimnames(ans)=dimnames(mat)
ans
}
Now look for the weakest dependence, ie, the partial correlation
closest to zero. Here it is -0.0827344. It is the partial
correlation between X2 and X4 given the rest.
From this we get the highest level tree, which has a single edge
with conditioned set {2,4} and conditioning set
{1,3,5}.
Next we look for the two edges in the next lower level tree. One
of the edgs must have {2, something} as the conditioned
set, where something ∈ {1,3,5}. The conditioning set is
{1,3,5} \ {something}. So the question is: how to find
that something? Notice that X4 plays no role
here. So we focus attention on the remaining variables, and apply
the same technique:
Look for the minimum absolute value in the row of X2. It
is 0.04253482, and occurs in the column corresponding to
X3. So the something we were looking for is 3.
Thus we get the edge 23|15.
Proceed similarly for the other edge. Here we focus attention on
all the variables except X2:
Look for the minimum absolute value in the row of X4
(which, by the way, is not the 4-th row). The least
absolute value is
0.3179254, and occurs in the column corresponding to
X1. So we get the edge 41|35.
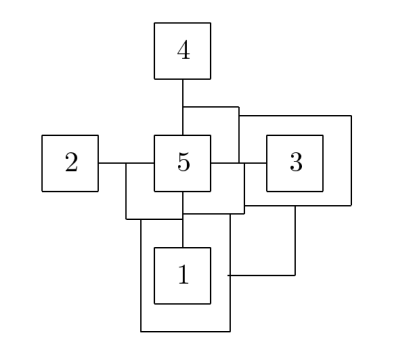
Proceeding thus, we get the following regular vine:
It is neither a C-vine nor a D-vine. Pictorially, it looks like this:
Estimating parameters
After we choose a vine (plus copulas and marginals with unknown
parameters) we need to estimate these parameters based on
data. As a joint distribution specified using vine-copula has
a density, we can always apply MLE. This may not be
computationally trivial. As may be expected, C-vines are easiest
to deal with. The details are given in here. See section 3.7 starting on page
25. For this course it is enough to read from page 25 to page 29
up to (and excluding) inference for D-vines.