Example: Let x be a DNA sequence like
aagtctcccggga.Consider a supervised classification data set consisitng of some DNA sequences classified into two classes.
tattcccgcaacttacgcca trait A gggaggtgacctaag trait A ... ... ggcccccgcctgcacagtatgggcg trait B aggctgccgggttcacatgc trait BHere a typical feature is a DNA sequence. Notice that the sequences may be of different lengths. A simple way to compare two such sequences (of possible unequal lengths) is to reduce each string to the frequency distribution of the all substrings of length 2, say. Then any sequence is mapped to a numeric vector of size 42 = 16. We show two example below:
ataat gtacgtg
aa 1 0
at 2 0
ac 0 1
ag 0 0
ta 1 1
tt 0 0
tc 0 0
tg 0 1
ca 0 0
ct 0 0
cc 0 0
cg 0 1
ga 0 0
gt 0 2
gc 0 0
gg 0 0
We can consider this is as
our φ : D → IR16 function, where D is the
space of all DNA strings. If we use the usual inner product
in IR16 then we get a kernel K(x,y) defined
on D × D as
K(x,y) = φ(x)'φ(y).For example we have
K(ataat, gtacgtg) = 1.◼ This kernel is called a string kernel. Obvious variants include changing the string length, allowing all substrings up to a given length. One may also tweak the kernel to customise it for particular cases, e.g., using a weighted inner product in IR16 where longer substrings are given higher weights.
Example: Consider the two sentences:
x1: to be or not to be that is the question.and
x2: please answer the question given below.We first create a dictionary which is the set of all the words occuring in the two sentences:
{to, be, or, not, that, is, the, question, please, answer, given, below }Now we get the two frequency distributions:
to be or not that is the question please answer given below
x1: 2 2 1 1 1 1 1 1 0 0 0 0
x2: 0 0 0 0 0 0 1 1 1 1 1 1
Notice how we use a common dictionary so that the
frequency vectors are all of the same length.
◼
Now we can define a bag-of-words kernel by taking a suitable
inner product of the frequency vectors. Lots of customising
options are available: weighting by length of the word, giving
higher weights to proper nouns (starting with capitals),
down-weighting commonly occuring words like "the", "a"
etc. Indeed, the ease of incorporating heuristic tweakings is one
of the main advantages of SVM.
φ(1) = (1,0) and φ(2) = (0,1).
Example: Suppose we have our symbols are the 26 lowercase letters, and a feature is a subset like {a,x,m,u,e,r,d}. There are 226 possible subsets of the entire alphabet (counting the empty subset). We can count which of these subsets occur in our feature. Thus each feature is mapped to 226-dimensional vector of 0's and 1's (mostly 0's).
If you take the Euclidean inner product in this 226 dimensional vector space, then you get the all possible subsets kernel. There are efficient ways to compute the kernel without explicitly computing φ. ◼ An easier (and more popular) variant is the so-called ANOVA kernel where we conider only subsets of a given size.
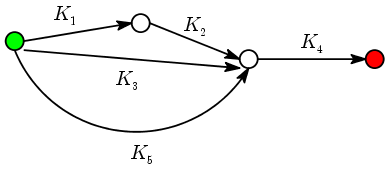
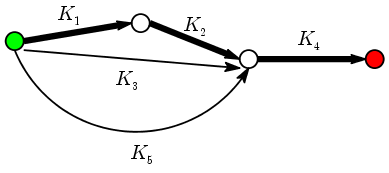
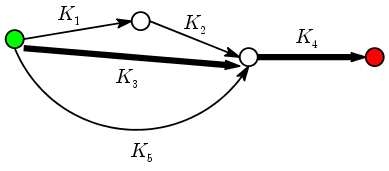
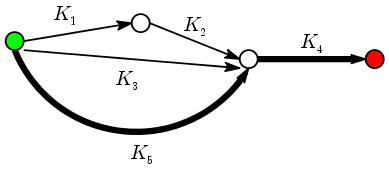
K(x,y) = ( K1(x,y) K2(x,y) + K3(x,y) + K5(x,y) ) K4(x,y).There cannot possibly be any doubt as to the tremendous flexibility of this kernel. We have freedom to choose the DAG, the start and terminal nodes, and the kernels for each arrow. In fact, this sheer flexibility might appear to be its disadvantage: How to choose all this to achieve good classification in a given problem? One possible answer to this question lies in the use of finite automata to recognise patterns. Roughly speaking these are directed graphs (often contain cycles) where you start from the start node, and follow the arrows according to some prescription based on the input that takes you to some terminal node. You classify the input according to the terminal node you arrive at. This approach works well if the input pattern is mathematically precise (e.g., syntax rule of programming languages). Graph kernels may be considered as an attempt to use the same approach allowing for some uncertainty.