The main reason behind analysing past data is to be able to apply
our findings to similar future data. So any meaningful
analysis must depend on our idea about what the
typical future data are going to look like. The following
example will clarify this point.
EXAMPLE:
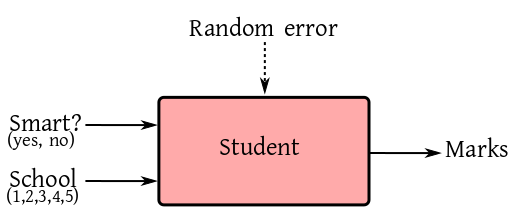
We want to study the effect of smart class rooms on student
performances in Bengali medium schools in West Bengal. Five schools are asked to
participate in the study. Each school takes a random sample of 50
students, and assigns a random half of them to smart class rooms,
while the remaining half is taught using traditional class
rooms. After 3 months of study, the students are evaluated in a
common examination. The marks are the responses. So the
box-diagram is as follows.
Here is a synthetic data set. The
following R session fits a 2-way ANOVA model without interaction
to it:
dat = read.table('mix.txt', head=T)
fit = lm(marks~., data = dat)
coef(fit)
How do you think we can use this report in the future? The
estimated smartyes may be used by other schools to
measure effectiveness of smart class rooms. But who will care
about the
estimated schoolB,..., schoolE? The
schools themselves may have some limited interest in comparing
themselves with schoolA, but nobody else will care
about that. The 5 schools are just some 5 schools. They
are like a sample of size 5 from the population of all similar
schools. Does this mean that we should drop the school effect
from our consideration (i.e., just merge that with random error)?
No, that is not good either, because the random error part is due
to all assignable causes. But the variation between schools is
definitely assignable. While we do not care about the performances
of these specific schools, we do care about the
variability among the schools.
To reflect this idea we make the school effect a random
effect.
$$
y_{ijk} = \mu + \alpha_i + b_j + \epsilon_{ijk},
$$
where the school effect $b_j$'s are
IID $N(0,\sigma^2_b).$ The $\epsilon_{ijk}$'s are
IID $N(0,\sigma^2_\epsilon),$ and are independent of
the $b_j$'s. Notice that $b_j$'s are not parameters any
more. This model has a new parameter $\sigma^2_b,$ which
measures the school-to-school variation.
Since our model has both a fixed effect
(the $\alpha_i$'s) as well as a random effect
(the $b_j$'s), we call it a mixed effects model.
There are two R packages that will allow you to fit a mixed
effects model: nlme (non-linear mixed effects)
and lme4 (linear mixed effects, version 4). The
latter is the more modern of the two, while former is far more
general (it can handle even some non-linearity). We shall
exclusively use the nlme package, as it allows
certain extra features that are useful in practice. Neither of
the two packages are installed by default in R. You'll need to
install the nlme package via:
install.packages('nlme') #Don't forget the quotes!
Once it is installed, we shall load the library, and invoke
the lme (linear mixed effects) function:
library(nlme)
lme(marks ~ smart, random = ~1|school, data=dat)
Let's understand the somewhat wierd syntax of this function. Our
familiar lm function required the first argument to
be a formula object (i.e, a specification of the
"box diagram"). The second argument (optional) was the name of the
data set. The lme function is similar, except that
it requires two formula objects, the first one for the fixed
effects, the second one for the random effects. The fixed effects
part is just as in the lm function. The wierdness is
in the random effects part. R likes to think of the $b_j$ as
a school-specific intercept term. For example, if you focus on
only the data from school 1, then model is
$$
y_{i1k} = \mu + \alpha_i + b_1 + \epsilon_{i1k},
$$
where $b_1$ is free of the running subscripts $i$
and $k.$ This school-specific intercept term is denoted
by 1|school. We have already specified the output
variable to the left of the ~ in the fixed effects
part. So we do not specify it any more. Thus, the random effects
part is just ~ 1|school. The random effects part
must always start with a ~.
Now, let's look at the output:
Linear mixed-effects model fit by REML
Data: dat
Log-restricted-likelihood: -759.8349
Fixed: marks ~ smart
(Intercept) smartyes
64.848 10.672
Random effects:
Formula: ~1 | school
(Intercept) Residual
StdDev: 9.861265 4.866941
Number of Observations: 250
Number of Groups: 5
Using our mathematical notation, this means:
$
\h \mu = $64.848, $\h \alpha_1 = 0, \h \alpha_2
=$ 10.672,
and
$
\h \sigma_e =$ 4.866941, $\h \sigma_b = $9.861265.
Note the rather ugly and counter-intuitive way $\h \sigma_b$
is presented in the output.
The output also mentions an estimation method
called REML. We have already learned
REML earlier.
Essentially the same method may be adapted to the mixed effects
model:
$$
y = X \beta + Z \gamma + \epsilon,
$$
where dispersion matrices for $\gamma $ and $\epsilon $
are, respectively, $D(\theta)$ and $R(\theta).$
REML still uses ML on $e = (I-P_X)y$ (no role of $Z$ here).
We again get
$$
\ell(\theta) = \log |\Sigma(\theta)| + w' \Sigma(\theta) ^{-1} w,
$$
where $\Sigma (\theta) = Z D(\theta) Z' + R(\theta).$ It is
numerical computation after that.
In a study related to poultry farming, we are interested in
seeing if playing soothing music has an effect on the size of
eggs laid by hens and ducks. A random sample of hens and ducks
are classified into two groups (one with and the other without
music). The following data are also collected about each bird:
hen or duck?
age
originating farm
number of eggs laid
Which of these should be considered as mixed effects?
Consider the mixed effect model
$$\begin{eqnarray*}
y_{11} & = & \mu + a_1 + \epsilon_{11}\\
y_{12} & = & \mu + a_1 + \epsilon_{12}\\
y_{21} & = & \mu + a_2 + \epsilon_{21},
\end{eqnarray*}$$
where $a_1,a_2$ are iid $N(0,\sigma^2_a)$
and $\epsilon_{ij}$'s are iid $N(0,\sigma^2_\epsilon).$
The $a$'s are independent of the $\epsilon $'s. Find
REML estimate of $\sigma^2_\epsilon $ and $\sigma^2_a$
based on the data $y_{11} = 2.3,$ $y_{12} = 2.5,$ and $y_{21} = 3.0.$
Write down the R syntax for lme to implement
the following mixed effects model:
$$
y_{ijk} = \mu + a_i + \beta_j + g_{ij} + \epsilon_{ijk},
$$
where $a_i$'s and $g_{ij}$'s are random effect
coeeficients and $\epsilon_{ijk}$'s are the error
terms. Let $i$ denote the "row" effect and $j$ denote
the "column" effect (i.e., you may use "row" and "column" as
variable names).
Write the following LME model in mathematical notation:
lme(y ~ x:gender, ~1|college)
Here x is a covariate, while gender
and college are factors.
Consider the model
$$
y_{ij} = \mu + \alpha_i + \epsilon_{ij},
$$
where $\epsilon_{ij}\sim N(0,\sigma^2)$ for some
unknown $\sigma^2.$ Will the ML estimator of $\sigma^2$
increase or decrease if the $\alpha_i$'s considered to be
random effects (iid $N(0,\sigma^2_a)$ for some unknown $\sigma^2_a$)?
Comments
To post an anonymous comment, click on the "Name" field. This
will bring up an option saying "I'd rather post as a guest."
 To reflect this idea we make the school effect a random
effect.
$$
y_{ijk} = \mu + \alpha_i + b_j + \epsilon_{ijk},
$$
where the school effect $b_j$'s are
IID $N(0,\sigma^2_b).$ The $\epsilon_{ijk}$'s are
IID $N(0,\sigma^2_\epsilon),$ and are independent of
the $b_j$'s. Notice that $b_j$'s are not parameters any
more. This model has a new parameter $\sigma^2_b,$ which
measures the school-to-school variation.
Since our model has both a fixed effect
(the $\alpha_i$'s) as well as a random effect
(the $b_j$'s), we call it a mixed effects model.
To reflect this idea we make the school effect a random
effect.
$$
y_{ijk} = \mu + \alpha_i + b_j + \epsilon_{ijk},
$$
where the school effect $b_j$'s are
IID $N(0,\sigma^2_b).$ The $\epsilon_{ijk}$'s are
IID $N(0,\sigma^2_\epsilon),$ and are independent of
the $b_j$'s. Notice that $b_j$'s are not parameters any
more. This model has a new parameter $\sigma^2_b,$ which
measures the school-to-school variation.
Since our model has both a fixed effect
(the $\alpha_i$'s) as well as a random effect
(the $b_j$'s), we call it a mixed effects model.